More people are tracking their food in 2026 than at any point in human history. The apps are faster, the photo recognition is better, and wearables now feed continuous activity data into platforms that claim to personalize your targets in real time.
And yet the average calorie tracking app user quits within two months. Self-monitoring rates in mobile health trials decline sharply after week three. The research on nutrition app effectiveness is, to put it generously, mixed.1
The problem is that most nutrition tools stop at the ledger. They record what you ate and compare it to a number. They do not know whether you trained today, whether last week's intake actually matched your goals, whether the plateau you hit is a measurement artifact or a real signal, or what single change would move you forward. The data sits there. Nobody interprets it.
A new category is beginning to fill that gap. It sits at the convergence of nutrition science, behavioral feedback systems, AI-assisted data capture, adaptive goal management, and coaching decision support. Here at Fuel, we call it performance nutrition intelligence.
This article covers what the evidence supports, where the category falls short, and what intelligent nutrition software actually looks like from the inside.
01Fuel is Performance Nutrition Intelligence
We built Fuel to be the product the world was missing. Everything that follows is a statement of what we think nutrition software owes the people who use it, where the category has failed to deliver, and what we are doing about it. These are the principles behind every product decision we ship to end users.
Performance nutrition intelligence is software that captures what you eat, integrates continuous activity data from both passive sources like accelerometer-based step counts and active sources like logged workouts with duration and exertion, understands all of that in the context of your goals and training load, provides adaptive targets that respond to your actual behavior rather than a static formula, detects patterns you would miss on your own across weeks and months of data, and closes a feedback loop between what you do and what you achieve.

This definition creates clear boundaries. A food tracker that logs calories but never adapts is a ledger. A general-purpose AI chatbot that writes meal plans has no stable record and no feedback loop. A CGM platform offers personalization signals around glycemic response, but it does not manage your macros, your training context, or your weekly adherence patterns.
The minimum viable version of the category requires four things.2
- Structured food capture with reduced friction and a correction workflow for refinement.
- A goal-aware target system that responds to real intake data, measured body weight trend, and continuous activity data from both passive movement and logged workouts.
- At least one feedback loop that closes over time, converting raw data into interpretation.
- Context-informed decision support that knows whether today is a training day and whether your current trajectory matches your stated goal.
The word performance matters. It assumes you care. It assumes you want the best for yourself. It assumes you are working toward a goal. It assumes you want to be the best version of yourself. That assumption relies on a dynamic data, changing with what your body needs on any given day. A recommendation that is correct on a rest day is wrong before a two-hour training session, and that context-sensitivity is what separates it from general dietary guidance.
02Why Now
The idea of software that coaches your nutrition is not new. What changed is that three enabling conditions converged at the same time. AI made food logging fast enough that people actually stick with it. Conversational interfaces made correction and interaction feel natural rather than tedious. And two decades of behavioral science research identified the specific software-solvable bottlenecks that were killing retention.
AI Logging Reduced Friction
The limiting factor in digital nutrition tracking has never been the desire to track. Research consistently shows that users who sustain tracking long enough to build a consistent dataset see meaningful outcomes. Most users do not sustain it, citing time as their primary reason. But when you dig in further to what truly happens, the reasons stack up fast. The database returns 47 entries for "chicken tikka masala" with wildly different calorie counts. The UX makes logging a homemade meal feel like filing a tax return. You skip the handful of chips you grabbed because it feels too small to bother with, then skip the whole weekend because you do not want to see the number. The friction is not just time. It is confusion, shame, and a system that treats every gap as your failure rather than its own design problem.1
AI-assisted logging has materially reduced that burden. The best photo recognition systems in 2025 and 2026 achieve mean absolute errors in calorie estimation of 10 to 15 percent in controlled conditions.3 Fuel narrows the practical error by estimating typical portions and relying on the user to scale up or down, rather than trying to guess exact amounts from a photo alone.
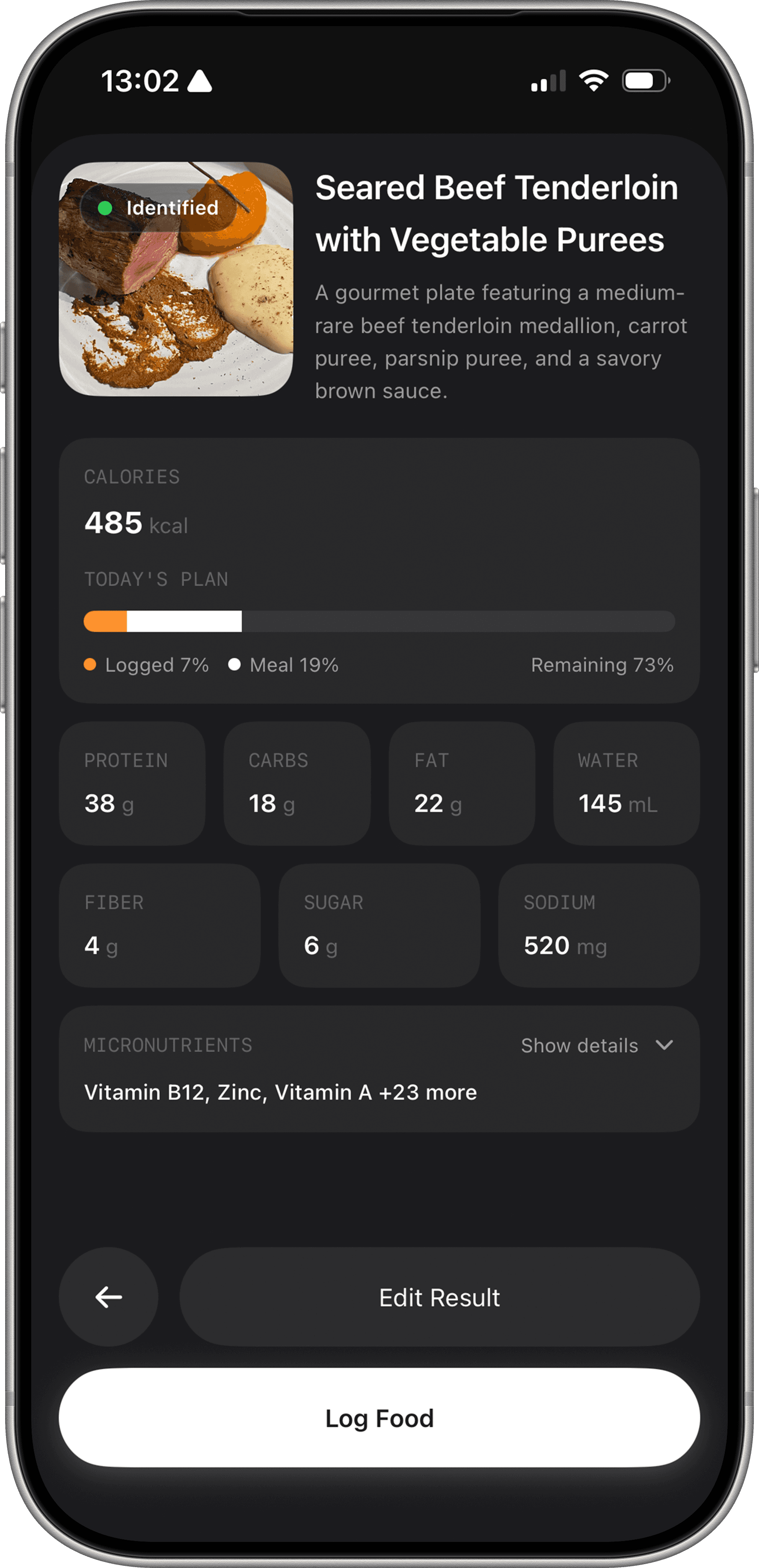
Conversational text and voice logging has become fast and semantically competent. Telling an app "grilled chicken breast, maybe 180 grams, with roasted sweet potato and olive oil" now produces results that are over 95 percent accurate. Most edits users make are preference adjustments, not corrections to glaring AI errors.
The critical design insight is that AI captures are drafts, not final records. They should be presented for confirmation or correction rather than silently accepted. This matters because accuracy errors compound downstream, and the correction workflow is where accuracy gets established.34
Reasoning Models Can Do Structured Nutrition Analysis
A skilled human nutritionist reviews your food log, cross-references it with your training schedule, checks your weight trend, considers your goal phase, and produces a recommendation. That process takes 15 to 30 minutes per client per week and costs the client $150 to $400 per month. A reasoning model in 2026 can do the same analysis in seconds, across every meal you have logged for the past six months, without forgetting a single data point or getting tired on client number 47.
In a January 2025 study published in Scientific Reports, researchers tested GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro against 1,050 registered dietitian exam questions. All model-and-prompt combinations passed with accuracy above 88%. The same paper reports CDR first-attempt pass rates of 61.5% for January through June 2024 and 88.4% for 2023. The exam is scored on an opaque 1 to 50 scale across 125 to 145 questions, with 25 required to pass. What is clear is that current LLMs can score in the passing range on the same material.
The advantage is not just speed. A reasoning model applies evidence-based protocols consistently across every interaction. It does not have an off day. It does not anchor on the last thing it read. It can hold your entire nutritional history, your training log, your weight trajectory, and the current sports nutrition literature in context simultaneously and reason across all of it. A human nutritionist working from memory and a 30-minute check-in cannot match that breadth of simultaneous consideration, no matter how experienced they are.
The cost difference is what makes this transformative. The level of weekly nutritional analysis and coaching feedback that previously required a $300-per-month professional relationship can now be delivered through software at a fraction of that price. That does not make human nutritionists irrelevant. It means the quality of guidance that was previously available only to people who could afford dedicated coaching is now accessible to anyone with a phone.
| Dimension | AI / reasoning model | Human dietitian |
|---|---|---|
| Protocol recall accuracy | 92-93% (RD exam) Consistent, no off days | 61.5% (first attempt) Variable, anchoring effects |
| Data breadth per review | 6 months in seconds Every logged meal retained | 30-min check-in window Relies on client recall |
| Availability | 24/7, instant response No scheduling required | Scheduled sessions $150-$400 / month |
| Complex clinical cases | Confident but incomplete Missing unknown context | Orders labs, adjusts plan Full clinical picture |
| Behavioral and emotional complexity | Pattern detection only No relational support | Empathy, motivation Therapeutic relationship |
For coaches who work with clients directly, this changes the quality of every interaction. A coach walking into a check-in used to rely on whatever the client remembered to share and whatever the coach had time to pull from the logs beforehand. Now the coach arrives with a complete synthesis of the past two weeks already done. Adherence patterns, macro distribution trends, training-day fueling gaps, and weight trajectory analysis are all computed and waiting. The conversation starts at the insight layer instead of spending the first 15 minutes on data review. The coach's expertise goes toward the judgment calls, the motivation, and the strategic adjustments that no model can replicate.
For the client, the same intelligence is available between sessions. The question that feels too small to text your coach about, whether to eat more carbs before tomorrow's long run or whether last night's dinner blew the weekly deficit, gets answered immediately instead of waiting for the next check-in or going unanswered entirely.
What Behavioral Science Revealed About Retention
The research literature on self-monitoring, adherence, and behavioral weight management has converged toward a surprisingly consistent finding: the mechanism by which tracking helps people is primarily attention and feedback, not accuracy.5
Most people eat on autopilot. They repeat the same meals, the same portions, and the same timing without ever questioning whether those habits serve their goals. Many genuinely believe their diet is healthy because nothing has interrupted the loop long enough to show them otherwise.
Neuroscience teaches us that being wrong feels the same as being right until the moment of awareness. Self-monitoring breaks that loop, holding an accurate mirror up to behavior and intake, redirecting cognitive resources toward eating decisions and forces a moment of honest assessment. Feedback on those decisions, even when it is algorithmically generated and only moderately personalized, improves both adherence to tracking and dietary outcomes.
A 2024 systematic review and meta-analysis found that algorithmic feedback in digital self-monitoring interventions produces improvements in dietary behavior, competitive in effect size with human-generated feedback in many contexts.5 A 2025 systematic review of mobile app-based dietary interventions found favorable changes that tend to peak around 12 weeks.1
Illustrative pattern based on Turner-McGrievy et al. and 2025 SMARTER trial data. Weeks 1–24.
That 12-week dropoff deserves a closer look. Part of it is novelty decay. But a bigger part is that most nutrition apps are designed like digital versions of a 12-week PDF program or a DVD workout series. They give you a plan, a set of targets, and a countdown. When the program ends, so does the engagement. They are not designed for what happens in month four when your body has adapted, your goals have shifted, and the original targets no longer apply. Long-term coaching requires a system that evolves with you, adjusting to your changing body composition, training demands, and life circumstances rather than running out of content.
That is the foundation performance nutrition intelligence is built on. The next question is what, specifically, it needs to solve.
03Twenty Years of Nutrition App Shortfalls
The first calorie counting apps launched in the mid-2000s. Twenty years later, the core experience is remarkably unchanged. The databases are bigger, the interfaces are cleaner, and some now recognize food from a photo. But the fundamental architecture of most products still does the same thing it did in 2010: record what you ate, compare it to a static number, and leave you to figure out the rest. That is why tracking apps have some of the highest download rates and lowest retention rates of any category in the App Store.
Static Calorie Targets
The vast majority of nutrition apps assign a daily calorie target at onboarding and never change it. The logic sounds reasonable: estimated maintenance minus a deficit. The problem is that it becomes wrong the moment anything changes, and things change constantly.
Total daily energy expenditure varies by several hundred calories day to day depending on non-exercise activity, training volume, sleep quality, and individual metabolic state. Weeks of consistent under-eating produce metabolic adaptation that lowers maintenance. A static target cannot account for any of these changes.6
The solution is an adaptive target system that uses real data inputs, including your food log, body weight trend, and training load, to infer actual energy balance rather than projecting it from a formula. When the system observes that your weight is not changing as predicted at your logged intake, it adjusts its inferred expenditure accordingly. This self-correcting logic is architecturally more important than per-meal calorie accuracy.7
Context Blindness
A calorie recommendation that does not know whether you trained today, how long, and how hard is a demographic average with your name on it. For performance-oriented users, this is the central failure of general-population nutrition tools. Eating the same macros on a rest day as on a two-hour run ignores the most important variable in the equation.
The International Consensus Conference on Optimizing Elite Athletic Performance, convened in November 2024 with 29 leading scientists, explicitly recommends that athletes scale energy, carbohydrate, and fluid intake to the demands of specific training sessions.8 A software system that makes this scaling automatic and visible translates expert coaching logic into a consumer interface.
Entry Burden
This is the principal cause of app abandonment. Research on dietary self-monitoring adherence consistently shows that engagement drops sharply in weeks two through four, with the largest predictor of early dropout being the time cost of accurate entry.1 Any platform that requires five or more minutes per meal to log accurately will lose most of its users before they generate enough data to benefit from it.
The design response is to make the accuracy-friction tradeoff an ongoing negotiation rather than a one-time choice. Capture fast with AI, correct quickly through conversational refinement when the AI draft is wrong, and build a saved meal library that reduces the entry cost of frequently eaten foods over time.
The Real World Is Restaurant-First
Most nutrition software still assumes the user is planning groceries, batch cooking protein, and building meals from raw ingredients in a controlled kitchen. That assumption no longer matches how a large share of people actually eat. Modern food decisions are often made in a drive-thru line, at a restaurant table, inside a coffee shop, or on a delivery app with twelve tabs open and thirty seconds of attention left. If coaching only works when someone is cooking from scratch, it is not coaching for the world people live in.
This matters because selection is where the decision happens. The useful moment is not two hours later when the meal has already been eaten and logged. The useful moment is when someone is deciding between the burger with fries, the rice bowl with double chicken, or the salad that looks healthy but lands with almost no protein and leaves them raiding the pantry at 10 p.m. Guidance has to show up at the point of choice, with enough context to make the better option obvious without asking the user to become a dietitian in real time.
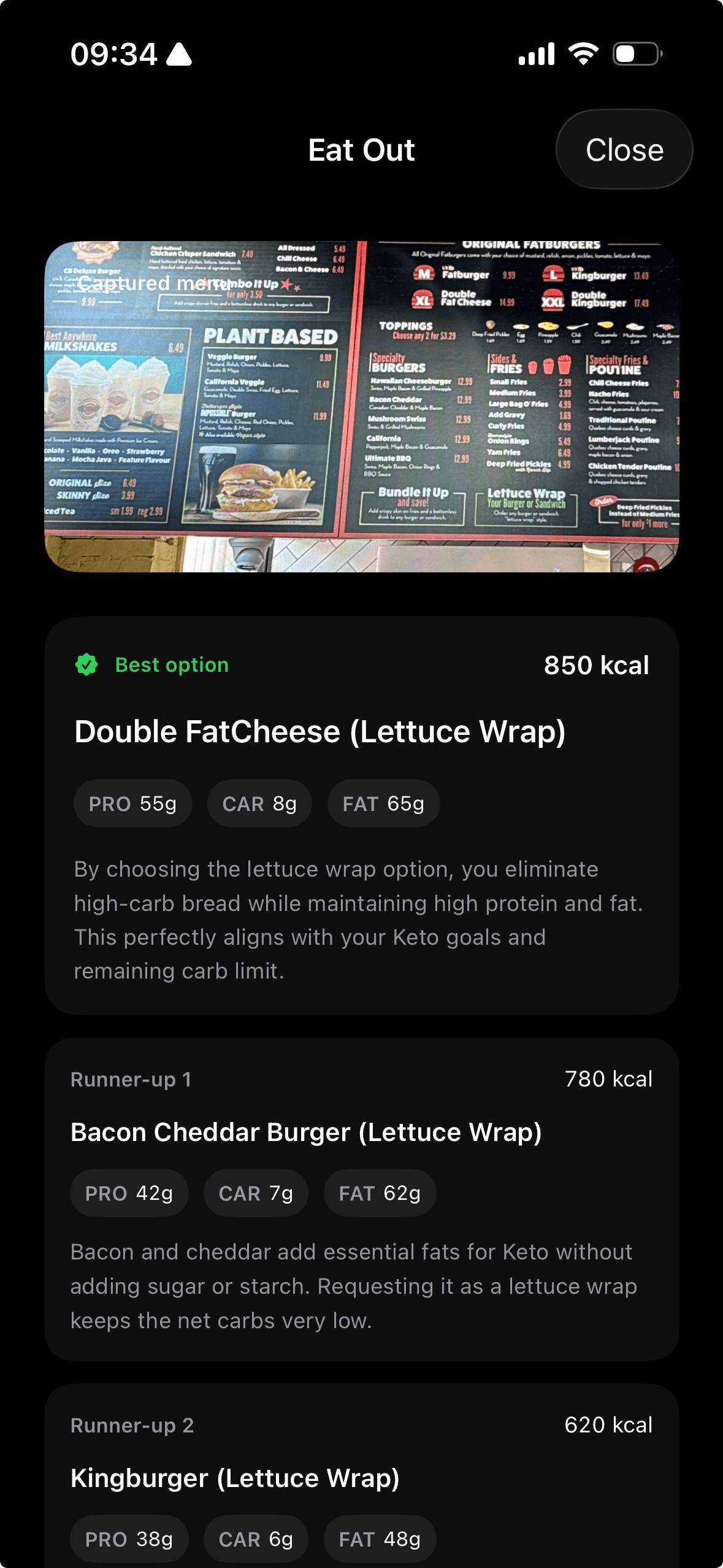
That is why nutrition intelligence has to extend beyond food logging into food selection. If someone eats out four times a week, the system should help them navigate menus, estimate tradeoffs, and choose the option that best fits the day's target and training context. Meeting people where they are means accepting that the modern nutrition environment is built around convenience, restaurants, and delivery, then designing coaching that works inside that environment instead of pretending it does not exist.
Missing Interpretation
Most users who track consistently cannot answer two weeks later whether their average daily protein was adequate, whether their weekends systematically blew their deficit, or whether their weight stall reflects a measurement plateau or a genuine maintenance. The data exists. Nobody synthesizes it.
A weekly coaching synthesis fills that gap by telling you exactly what to change and why. Here is what that looks like in practice.
Your protein averaged 118g against a 150g target, concentrated at dinner with almost nothing at breakfast. Add 30g at breakfast through eggs or Greek yogurt and you close that gap without changing anything else. Your weekday calories were on target but Fridays and Saturdays ran 200 over consistently, which zeroed out the deficit. Cut one drink or one appetizer on those nights and your weekly balance lands where it should. Do those two things and your weight trend, which has been flat for three weeks, starts moving again.
That is actionable. A calorie count next to a red or green number is not.
Coach Scalability
Some nutrition apps offer access to a human coach as an upgrade tier. A skilled coach reviews your food log in the context of your training schedule, notices patterns in your compliance, and produces personalized weekly feedback that generic software cannot match. The problem is that this model prices most people out. Dedicated nutrition coaching typically runs $150 to $400 per month, and even at those rates, a coach managing 30 to 100 clients does not have the cognitive bandwidth to review every client's daily log in detail. What gets sacrificed is depth: coaches review aggregate data rather than detailed logs and schedule check-ins less frequently than would be optimal for adherence.
The result is a gap between what coaching could deliver and what most users actually receive. The users who would benefit most from structured weekly feedback, pattern detection, and training-aware adjustments are often the ones who cannot justify the recurring cost.
A platform that automates the data synthesis layer, generating structured, training-integrated nutrition summaries and surfacing compliance patterns algorithmically, changes the economics on both sides. For coaches, it shifts cognitive load from data collection to interpretation and relationship, allowing the same coach to service more clients at higher quality. For the majority of users who will never hire a coach, it delivers the continuous feedback loop that was previously locked behind a premium price point.2
Lack of Memory
Most nutrition apps start over each time. There is no accumulation of insight about how you specifically respond to higher protein, how your compliance degrades under work stress, what your consistent tracking blind spots are, or which types of meals you systematically underestimate.
This absence of memory also helps explain the 12-week compliance dropoff in current apps. Users see the same generic prompts and suggestions recycled week after week. What started as useful feedback degrades into background noise because the system never learns anything about the person using it.
Building a memory layer that stores and retrieves this kind of longitudinal behavioral data, and applies it to current recommendations rather than retreating to population averages, is one of the clearest differentiation opportunities the category has in 2026.
No Contextual Coaching
The thread running through all of these failures is the absence of coaching.
A human nutrition coach reviews your week, knows your training schedule, remembers that you undereat after long runs, and tells you what to change next week. No consumer nutrition app in the past twenty years has delivered that combination of daily awareness and weekly synthesis.
Some track well. Some provide static meal plans. Some offer a chatbot that answers questions without memory or context. None have closed the loop between what happened today, what it means this week, and what you should do differently starting Monday.
But even that framing undersells what people actually want. "What to do next" matters in the first few weeks. After that, most people stop following instructions they do not understand. They want to know why they received the grade they did. Why their energy crashed on Thursday when Tuesday felt great. Why the scale moved this week after stalling for three. Why more carbs on leg day is the right call for their body right now. The why is what turns compliance into understanding, and understanding is what makes behavior change last. That is the gap performance nutrition intelligence exists to fill.
04Scientific Foundations
Every feature in this category makes a scientific claim, whether the product says so explicitly or not. Adaptive calorie targets claim that energy expenditure changes over time. Training-day carb scaling claims that periodization matters for performance. Weekly feedback claims that self-monitoring drives behavior change. Some of these claims have decades of evidence behind them. Others are running ahead of what the research can actually confirm.
Energy Balance and Adaptation
Total energy balance governs body composition change. What the simplistic version misses is that energy expenditure is variable. Non-exercise activity thermogenesis (NEAT) fluctuates by several hundred calories per day in response to changes in food intake. Adaptive thermogenesis in response to sustained caloric restriction is well-documented.6 A static calorie prescription becomes progressively wrong over weeks of dieting. For a deeper look at why this happens and how to fix it, see adaptive calorie targets.
A system that updates targets based on actual weight trend data is the correct approach given the science. Trend-based inference, where the system calculates your actual expenditure from logged intake and observed weight change, handles noise gracefully and corrects for systematic user-level logging errors without requiring perfect per-meal accuracy.7
Protein Dosing and Distribution
The protein literature is among the most robust in sports nutrition. For resistance-trained individuals, 1.6 to 2.2 g/kg/day is consistently associated with greater fat-free mass gains than lower intakes across multiple systematic reviews and meta-analyses. The upper range becomes more relevant during caloric deficit and for older adults.9
On distribution, there is strong experimental evidence that evenly distributing protein across three to four meals produces a meaningfully higher 24-hour muscle protein synthesis rate than concentrating intake at one or two meals. Paddon-Jones and colleagues showed approximately a 25 percent higher fractional synthetic rate with even distribution.9
For software, this means protein targets are well-supported by evidence, distribution feedback is actionable, and timing nudges are directionally correct but should be presented as optimizations rather than requirements.
Carbohydrate Periodization
Scaling carbohydrate availability to match training load, known as carbohydrate periodization, has strong mechanistic support and is explicitly recommended in the 2024 international elite athlete consensus statement.8 High-intensity sessions require adequate glycogen for performance. Low-intensity sessions can be completed under lower carbohydrate availability.
The performance outcome evidence is weaker than the mechanistic case would suggest. A 2021 meta-analysis found no significant overall effect of periodized carbohydrate restriction on endurance performance (SMD = 0.17, non-significant).10 The practical interpretation: a platform that increases carbohydrate targets on training days and reduces them on recovery days is solving a real practical problem even if it cannot point to a direct performance improvement from restriction in a controlled trial.
Self-Monitoring and Adherence
A systematic review across 59 randomized behavioral weight loss trials found that 12 out of 18 studies examining the relationship showed a significant positive association between dietary self-monitoring adherence and weight loss outcomes.5 A 2025 mHealth trial confirmed this in a 12-month digital health context.11
The critical caveat is that high-adherence trackers may be high-motivation participants generally, partially confounding the causal claim. The dose of self-monitoring needed for effect remains uncertain, but evidence points toward consistency over comprehensiveness. Tracking two or more eating occasions per day predicted weight loss better than total tracking days in one six-month study.
For software design, this evidence supports investment in anything that reduces the cost of consistent tracking and feedback mechanisms that reinforce the self-monitoring behavior itself.
Measurement Error
One of the most important facts about nutrition tracking is that it is systematically inaccurate. Research using doubly labeled water shows that people underreport caloric intake by 20 to 50 percent depending on body weight status, with obese subjects underreporting by an average of 47 percent in the landmark Lichtman et al. study.12 This is a function of portion estimation error, omissions of cooking fats and condiments, and the fact that food labels carry a plus-or-minus 20 percent legal tolerance in many jurisdictions.
Sources: Fuel internal user testing across 3 continents (2026); Hooker & Carey (underestimation data).
JMIR scoping review Nov 2024 (AI controlled); University of Sydney 2024 (AI real-world mixed dishes).
AI photo logging improves on this. The best systems achieve mean absolute errors of 10 to 15 percent in controlled conditions.3 But accuracy degrades for mixed dishes, culturally diverse foods, and home-cooked meals where invisible calorie-dense additions like oils and sauces are not captured. A 2024 University of Sydney study found beef pho calories overestimated by 49 percent and bubble tea underestimated by 76 percent by AI image recognition apps tested under real-world conditions.4
The correct design response is to build systems that are robust to noise. An adaptive target system that triangulates actual energy balance from weight trend data corrects for systematic user-level errors without requiring perfect per-meal accuracy. If you are consistently 15 percent low in your logging, the system observes that your weight is not changing as predicted and adjusts its inferred expenditure accordingly.7
The Limits of Personalization
The precision nutrition hypothesis, that individuals respond so differently to specific foods that population-average guidelines are insufficient, has been the central bet of consumer nutrition technology since the landmark Zeevi et al. study in 2015 showed that glycemic responses to identical foods vary substantially between individuals.13 CGM-driven personalization products are built on this premise.
For a broader look at how leading researchers frame nutrition personalization, see the Huberman Lab nutrition advice roundup. The evidence for meaningful clinical utility of CGM-guided personalization in healthy, non-diabetic individuals remains emerging rather than established. Most consumer apps in 2026 operate at one of two tiers: demographic-based targets (everyone in your weight, age, and activity category gets this target) or behavior-responsive adaptation (targets adjust to your actual intake and weight trend). The genuinely individualized tier, where targets reflect your specific metabolic response informed by biomarker data, exists in clinical contexts but has not been validated for consumer-grade autonomous recommendation in healthy populations.2
Most apps that advertise personalized nutrition are calculating your targets from your age, sex, weight, and activity level. That is demographic segmentation with better branding. Genuine personalization requires capturing what you eat, adapting targets to how your body actually responds, detecting patterns across weeks of data, and closing a feedback loop between your behavior and your recommendations.
05How Performance Nutrition Intelligence Works
A platform in this category has to capture what you eat with minimal friction, set targets that adapt to your real behavior, detect patterns you would miss on your own, and close a feedback loop that improves over time. Each layer depends on the one before it. Get capture wrong and the data is unreliable. Get targets wrong and the feedback is meaningless. Skip the feedback loop entirely and you have built another tracker.

Capture
The first layer is food capture. The relevant approaches in 2026 are photo recognition, voice logging, conversational text entry, barcode scanning, and saved-meal retrieval. No single modality is best for all scenarios. The strongest platforms offer multiple modes and let you switch based on context.
The LLM adds clear value here for two specific functions: semantic parsing of natural-language food descriptions into structured nutritional data, and multi-turn conversational correction. These are tasks where the fluency and contextual awareness of language models translate directly into lower friction and higher accuracy than rule-based systems could achieve.3
Adaptive Targets
The second layer takes inputs from your food log, weight trend, training calendar, and goal parameters, and produces daily macro and calorie targets that are contextually appropriate rather than static.
The most important input most platforms still ignore is real-time activity data. Accelerometer data from a phone or wearable captures ambient movement throughout the day, not just logged workouts. Platforms like Apple Health aggregate step counts, active calories, logged workouts with duration and exertion levels, and resting energy estimates into a continuous activity signal that a nutrition system can consume without the user doing anything.
A rest day where you walked 12,000 steps and a rest day where you sat at a desk for nine hours are fundamentally different energy demands, and a target system that treats them identically is leaving the most accessible data on the table.
Training-context adjustment, where carbohydrates and total energy increase on training days and decrease on recovery days, is one form. Adaptive energy expenditure calculation, where the system infers actual caloric maintenance from weight trend data rather than projecting it from formulas, is another and arguably more important form. The strongest version combines both with continuous wearable data so that targets reflect what you actually did today, not what you told the app you planned to do.7
Computing adaptive targets in 2026 requires a range of techniques matched to the demands of each calculation. On-device algorithms handle the fast, deterministic work like daily calorie adjustments and macro splits where latency matters and the math is well-defined. Machine learning models detect patterns in weight trend data and activity signals that rule-based systems would miss. Language models contribute where reasoning flexibility is needed, like interpreting unusual training loads or explaining why a target changed. The design challenge is choosing the right technique for each job based on speed, reliability, and the cost of being wrong.14
Pattern Detection and Feedback
The third layer is where the system's intelligence becomes most visible over time. Patterns that you and even your coach might miss become apparent to a system with access to structured longitudinal data. Systematic weekend compliance failures. Protein concentrated at dinner with almost nothing earlier in the day. Consistent under-fueling in the 24 hours before your hardest training sessions. Gradual caloric drift upward across a six-week period so slow you would never notice it day to day.
These patterns only emerge from weeks of data, and they require the system to look across meals, days, and weeks rather than evaluating each entry in isolation. A daily log tells you what happened today. Pattern detection tells you what keeps happening and whether it is helping or hurting your trajectory.
The minimum viable version of this layer is a weekly synthesis that answers how this week compared to target, what the consistent gaps were, and what single change would have the largest impact going forward. The more sophisticated version builds a behavioral profile of your consistent blind spots, your high-compliance contexts, and your trigger patterns over months of data. That profile allows the system to personalize both the content and the timing of its feedback. A user who consistently falls off on weekends needs a Friday afternoon nudge, not a Monday morning summary of what went wrong. A user who under-fuels before long sessions needs a pre-workout prompt on those specific days, not a generic daily reminder to eat enough carbohydrates.5
Closed-Loop Adaptation
The fourth and most consequential layer is the closed loop between what you do and what the system recommends. Without this layer, the software is a tracker. With it, the software learns.
Imagine you have been hitting 1,800 calories every day for three weeks. The scale has not moved. You are doing everything the app told you to do and nothing is happening. In a traditional tracker, this is where most people quit or slash their intake by another 300 calories because they have no other information to act on. A closed-loop system looks at the same data and reaches a different conclusion. Your weight is stable at 1,800, which means 1,800 is your actual maintenance, not the 2,100 the original formula predicted. The targets shift, you understand why they shifted, and the next three weeks are built on observed data about your body instead of a guess that stopped being accurate the moment you started.
The first time this loop fires, the correction is rough because the system has limited data. By month three, it knows your logging tendencies, your weekend patterns, and how your weight responds to different intake levels. The corrections become more precise and more confident as data accumulates. A system that has six months of your behavior is fundamentally different from one that has two weeks, even if the interface looks the same.
The loop also has to handle phase transitions. Someone who finishes a cut and moves into maintenance or a building phase changes the target, the expected weight trajectory, and the interpretation of every data point. Most apps effectively reset to zero at this boundary. A system with a real closed loop carries forward everything it learned about your metabolism and behavior into the new phase and recalibrates from a position of knowledge rather than starting over with population averages.
06The Market in 2026
The nutrition app market in 2026 is large, fragmented, and poorly differentiated. Understanding where products actually sit requires looking past category labels. For a comprehensive comparison, see our best AI nutrition apps guide.
Log-First Trackers
MyFitnessPal has the largest food database and highest name recognition, but its user-generated entry system produces inconsistent and sometimes dramatically incorrect nutritional data. Cronometer occupies a premium position on data accuracy with a curated, lab-verified database of over 84 nutrients and added photo logging in late 2025. MacroFactor is the most analytically sophisticated tracker in this segment. Its adaptive expenditure algorithm is evidence-informed and well-implemented. Its limitation is that it requires significant user investment in understanding what the data means and how to act on it.7
The user complaints across these platforms are remarkably consistent. MyFitnessPal users describe barcode scanning locked behind a $19.99/month paywall as "insane" given that scanning is the most basic logging action. Intrusive ads surface mid-log with what reviewers call "gross" food imagery. Fitbit integration double-counts workouts by logging the session and then adding step-based calorie adjustments from the same activity. Long-time users report losing months of weight history without explanation. MacroFactor users outside North America describe significant gaps in branded food coverage and missing EU barcode support that make the app effectively unusable without manual entry for everything. Even enthusiastic MacroFactor reviewers acknowledge the onboarding is "annoying at first" and the workflow demands more from the user than most competing apps. The pattern is the same across the segment. These products solve one problem well and leave the user to absorb the cost of everything they do not solve. For a structured comparison of these platforms, see our detailed comparisons and reviews.
Photo-First AI Loggers
Cal AI, SnapCalorie, and Foodvisor have solved an important piece of the friction problem. SnapCalorie's documented 16 percent mean error rate for photo logging is a real technical achievement. The dominant user feedback across these platforms is that logging is fast but the data does not tell you anything useful beyond the per-meal calorie count. The coaching intelligence layer remains largely undeveloped.
Cal AI's accuracy problems go deeper than the coaching gap. In head-to-head testing, Cal AI missed calories by 20 percent compared to Fuel's estimates. Photo recognition consistently underperforms, frequently misidentifying dishes entirely and assigning macro splits that do not match actual food composition. Users report basic arithmetic errors where gram values double or macro totals simply do not add up, with no way to manually correct the entries. Barcode scans return values that diverge from package labels on fiber and sugar. Corrections do not persist between scans. Speed means nothing if the numbers are wrong and the user has no way to fix them.
Coaching-Integrated Platforms
Noom takes adherence and behavior change seriously with an extensive behavior change curriculum and human coach access. It has a relatively robust clinical literature behind its approach. Welling and Fitia offer conversational AI nutrition coaching with adaptive calorie guidance. Their limitation for performance-oriented users is the absence of training-context awareness, macro-level precision, and the coach-facing tools that multi-client operators need.
Noom's coherent behavioral philosophy is undermined by structural app failures that make it unreliable for daily use. The app frequently fails to load, and the most common fix is uninstalling and reinstalling, which resets all user preferences and settings. Food logging is manual search only with no barcode scanning, photo logging, or voice input. Users cannot copy meals from previous days. Manual food additions do not register correctly, leading to inaccurate calorie totals. Customer service is described consistently as "effectively unreachable" across user reviews. At approximately $70 per month, Noom is among the most expensive options in the category, and that price buys a behavioral curriculum delivered through an app that cannot reliably perform the basic daily task of recording what you ate.
Performance-Specific Platforms
Fuelin was an early pioneer, built around training-calendar integration and sports dietitian-designed protocols for endurance athletes. MAVR positions as the automated version, with AI-driven fueling adjustments that respond to training load changes without requiring human coach updates.
Fuel Nutrition occupies a distinct niche within this segment. It is built around the coaching interface model, treating AI as the mechanism for making coaching workflows continuous rather than episodic. Conversational logging with editable AI capture, adaptive target calculation that integrates Apple Watch activity data and weight trends, daily feedback and grading, and an in-depth weekly coaching review layer address all four architecture layers in a consumer-accessible form. The product's philosophy, that the bottleneck is behavior continuity rather than recommendation quality, is aligned with the adherence literature.15
Fuel operates at the behavior-responsive personalization tier. It adapts targets to your actual intake, weight trend, and activity data. It does not account for individual differences in nutrient absorption, gut microbiome composition, or disease states that require clinical dietitian involvement, and no consumer software platform in 2026 credibly does. The product works best for people who are training toward something and willing to engage with their data over weeks and months. The frontier beyond that, integrating personal medical data and passive food capture through wearables, is where the category goes next, but it is not where any consumer product reliably operates today.
07The Hard Problems That Remain
Defining a category is easier than delivering on it. Performance nutrition intelligence solves real problems that trackers and static meal plans never could, but every product in the space still faces challenges that range from solvable with current technology to dependent on breakthroughs in medicine, sensor hardware, and model capability that have not arrived yet. The problems worth naming are the ones where progress is possible now and where honest acknowledgment matters more than marketing around the gaps.
The Personalization Problem
The word "personalized" appears in the marketing materials of virtually every nutrition app, regardless of what the product actually does. In most cases, personalization means the app calculated your targets using your age, sex, weight, height, and activity level, then showed them to you with your name on the screen. That is demographic segmentation.
The behavior-responsive tier, where targets adjust based on your actual intake, weight trend, and activity data, is a solved problem. We built Fuel around this. Your targets change based on what you actually did and how your body actually responded. That is a meaningful improvement over static formulas and it produces better outcomes for most users.
But true personalization goes further than behavior-responsive adaptation. How your body specifically responds to 80 grams of carbohydrates before a morning run versus an evening session. Whether you partition calories more efficiently toward muscle at higher protein intakes or whether the extra protein is redundant for your physiology. How your recovery timeline changes when you shift meal timing by two hours. These are n-of-1 questions that population averages cannot answer and that behavior-responsive algorithms can only approximate through slow observation over months of data.
Answering them with real confidence requires integration with deeper testing. Blood panels, CGM data, gut microbiome profiles, and metabolic rate assessments produce individual signals that could inform targets in ways that logged intake and scale weight alone cannot. The algorithms that translate those signals into daily actionable recommendations for a single person, rather than a population average, are still being developed. The data exists in clinical and research settings. The consumer software that reliably closes the loop between individual biomarker data and daily nutrition targets for healthy people does not, and any product claiming otherwise in 2026 is ahead of its evidence.13
The Limits of Correct Answers
Hallucination has not disappeared, and newer reasoning models are not automatically safe nutrition authorities. For a closer look at what LLMs actually do well and where they introduce risk, the distinction matters. The 2023 healthcare AI and ChatGPT literature frames these systems as useful assistants for decision support, documentation, and patient education when their outputs are checked against current evidence, clinician judgment, and patient-specific context. In nutrition software, that is the right bar: use models for structured macro calculations, training-context interpretation, and periodization logic, then design the product so uncertain or clinical assumptions are exposed instead of hidden.14
The harder problem is that a model can give a completely correct answer that is completely wrong for you because it is missing a piece of context that would change everything. A model that recommends 2g/kg protein for a resistance-trained adult is following the evidence perfectly. For someone with undiagnosed kidney disease, that recommendation is dangerous. A model that scales carbohydrates up before a long endurance session is applying sound sports nutrition. For someone with a genetic condition affecting glycogen storage, the same advice fails. The model is not hallucinating. It is answering a question it does not have enough information to answer correctly, and it does not know what it does not know.
This is the same blindspot human experts have. The best sports dietitian in the world gives different advice after seeing bloodwork than before seeing it. The best cardiologist changes the plan after the genetic panel comes back. Expertise without complete information produces confident, well-reasoned, wrong answers. AI models have the same limitation at higher speed and scale.
The design implication is not more guardrails against fabrication. It is building systems that surface what they do not know rather than burying uncertainty inside confident recommendations. A system that says "this recommendation assumes normal kidney function, which we have not verified" is more trustworthy than one that silently assumes it. The goal for the category is not omniscient AI. It is AI that is transparent about the boundaries of its knowledge and clear about when a human clinician needs to be in the loop.
Where Software Stops Working
Software only works within the conditions it was designed for, and those conditions include both the user's situation and the user's willingness to show up. When both of those hold, the results are real. People who track their food consistently lose more weight, hit their protein targets more often, and maintain dietary changes longer than people who do not.5 Software never gets tired of you. It does not judge you for logging a 4,000-calorie Saturday. It is available at 2 AM when a human coach is not. It can process six months of your data in seconds and find the pattern that explains your plateau.
Willingness to show up breaks when life intervenes. A job loss, a health scare, a month where you cannot face the app after a weekend that went sideways. Most people who stop tracking do not make a conscious decision to quit. They miss a day, then two, then the gap feels too large to bridge and they never come back. No algorithm in 2026 knows how to reach across that gap and bring someone back in a way that feels like support rather than a notification.
The user's situation breaks the contract when they fall outside the population the software was built for. Software is designed for the cases its developers anticipated, and in practice that means the middle of the distribution. The user with a straightforward goal, a stable relationship with food, and a predictable training schedule gets a product that works. The user managing disordered eating, athletic RED-S risk, or a complex medical history hits the boundary where the product was never designed to operate. Most nutrition apps do not even detect that boundary. They continue serving the same recommendations to someone who needs clinical intervention that they serve to someone training for a half marathon.
Both of these failures point to the same design challenge, and it is the most important one the category faces. The next generation of performance nutrition intelligence needs to recognize when it has stopped being useful to the specific person using it. Today, the responsible design choice is to make those boundaries visible and direct people toward the clinical professionals who can help. But the boundaries themselves are not fixed. As individual health data becomes richer and software gains the ability to adapt its own logic per user rather than running the same code for everyone, the range of people it can serve effectively will expand. Software that can rewrite its own recommendations based on your specific medical history, your biomarker data, and your behavioral patterns is software that moves the boundary outward. That is not where any consumer product operates in 2026, but it is the trajectory we are on.8
Privacy and Trust
Food logs are intimate data. Weight trend data is sensitive. The combination of food logs, body weight, training data, and behavioral patterns from a health application constitutes a detailed profile of your physical and behavioral state. Users should understand what data is stored, how long it is retained, whether it is sold or licensed to third parties, and how it is used to train product AI models. Trust is the prerequisite for the long-term engagement that makes any coaching system effective.
The computational reality makes this harder than it should be. The reasoning models that power adaptive targets, pattern detection, and coaching feedback in 2026 cannot run on a mobile device. They require cloud infrastructure, and that will likely remain true for the rest of this decade. On-device models are improving, but the gap between what a phone can run and what a capable reasoning model requires is measured in orders of magnitude, not incremental improvements. Every nutrition app that uses AI for anything beyond basic local calculations is sending your food logs, weight data, and behavioral patterns to a server.
Apple's platform adds an ironic layer to this. iOS is marketed as the most privacy-conscious mobile operating system, and in many respects it is. But Apple's aggressive background processing restrictions prevent apps from running predictable, around-the-clock computations on-device. Background tasks are throttled, deprioritized, and killed to preserve battery life and system performance. The practical result is that even apps that want to do more processing locally are forced to move their computation into the cloud because iOS will not let them run reliably in the background. The platform that promises the most privacy creates the infrastructure constraint that makes cloud dependency unavoidable.
Users deserve to know this. The question to ask any nutrition app is not whether it uses AI, because they all do or will. The question is where your data goes when the AI runs, how long it stays there, who else can access it, and whether the company treats your behavioral and body composition data as a product to be monetized or a trust to be protected.
08What Each Audience Should Know
The same app solves different problems depending on what you are training for. A lifter in a cut, an endurance athlete peaking for a race, and a coach managing 50 clients all need the intelligence layer, but they need it to do different things.
For Lifters and Physique-Focused Users
You already know that protein matters and that calories determine whether you gain or lose. What you probably do not know is whether your execution across a full week actually matched your intent. For a detailed framework on managing this, see fat loss and muscle preservation. You hit your protein target Monday through Thursday but averaged 30g below on weekends. You held your deficit on training days but overate on rest days by enough to erase half of it. You have been in a surplus for six weeks and the scale is moving, but you have no idea whether the gain is mostly muscle or mostly fat because nobody is looking at the rate of change relative to your training volume. You are doing the work in the gym. You are logging the food. And you still cannot answer the most basic question about whether your current phase is actually working.
That answer shows up when the system looks at your full week and tells you what happened. Your protein distribution is back-loaded and your morning sessions are suffering for it. Your weekend surplus is canceling out three days of your deficit. Your rate of weight gain over the past month suggests you are adding fat faster than muscle at your current surplus, and dropping 200 calories on rest days would tighten that ratio without affecting recovery. You walk into Monday knowing exactly what to adjust instead of repeating the same week and hoping for a different result.9
For Endurance and Hybrid Athletes
You know what bonking feels like. You know the difference between a long run where your legs had something left and one where you crawled through the last 45 minutes wondering why you signed up for this. The answer is almost always fueling. Whether you ate enough carbohydrates in the 24 hours before the session. Whether you took in enough during it. Whether the three days leading into your hardest training block set you up to perform or set you up to suffer. The research on scaling carbohydrate availability to session demand, maintaining protein during high-volume blocks, and managing race-week nutrition is extensive and directly applicable.8
The problem is that nobody wants to do the math. Translating those protocols into what you actually eat on Tuesday night before a Wednesday tempo run, or how to load for a Saturday long run that starts at 6 AM, requires applied sports nutrition knowledge that most athletes either do not have or do not have the time to apply meal by meal. A training-integrated platform does that translation automatically. It sees your schedule, adjusts your targets to the session ahead, and tells you when your intake over the past three days has put you on track to underperform before you find out the hard way at mile 16.
For Nutrition Coaches
You have 50 clients. You know you are not giving each one the attention their food log deserves. You skim the daily totals, check whether they logged consistently, and save your real analysis for the ones who are visibly struggling or about to check in. The clients in the middle get less of your time. They are mostly compliant but slowly drifting off target in ways that will matter in four weeks, and you will not catch it until the check-in where the scale has moved in the wrong direction and the client is frustrated.
A platform that processes every client's week and surfaces the patterns you would catch if you had unlimited time changes the shape of your practice. You stop spending your mornings pulling numbers out of logs and start spending them on the conversations and judgment calls that actually require you. The client who was quietly drifting gets flagged before they hit the wall. The client who is executing well gets confirmation that reinforces their compliance. Your attention goes where it has the most impact instead of being spread thin across data entry that software handles better than you do.2
For Health-Tech Builders
Any team with access to current AI infrastructure can ship a food logger in 2026. Photo recognition, voice entry, and conversational NLP are available off the shelf. The logging layer is commoditizing fast, and competing on logging speed or accuracy alone is a race to parity that every serious team will finish within a product cycle or two.
The hard part is everything that happens after the food is logged. Adaptive target logic that responds to real behavior over weeks. Pattern detection that works across noisy, incomplete data from users who skip meals and forget to log snacks. Feedback systems that produce specific, actionable interpretation grounded in training context and longitudinal trends. That intelligence layer is where the defensible value lives, and it requires deep integration between nutrition science, behavioral modeling, and ML infrastructure that cannot be assembled from APIs in a sprint. The teams that treat logging as the foundation and build intelligence on top of it will define the category. The teams that stop at logging will wonder why retention flatlines after onboarding.
09Future Outlook
The version of performance nutrition intelligence that exists in 2026 is built on what software can observe about you today. Your food log, your weight trend, your activity data, your training schedule. That is already enough to produce adaptive targets, weekly coaching synthesis, and pattern detection that outperforms anything the category offered three years ago. But it is a fraction of what becomes possible as health technology and medicine converge over the next decade.
The trajectory points toward a world where your nutrition platform knows your bloodwork, your genetic predispositions, your gut microbiome profile, your sleep architecture, and your real-time metabolic state. Where recommendations are not just responsive to your behavior but informed by your biology in ways that population averages could never approximate. That world is not here yet. The infrastructure is being built across wearable hardware, clinical diagnostics, and AI model capability, and the platforms that are architected to integrate those signals as they become available will deliver a version of personalized nutrition that the current generation can only gesture toward. What follows is what improves in the near term and what remains stubbornly difficult.
What Gets Better
Food recognition has already improved dramatically. Leading vision models in 2026 correctly identify culturally diverse cuisines from around the world, including dishes that are not served in the westernized versions of those restaurants that earlier training datasets were built on. A bowl of authentic Sichuan mapo tofu, a West African jollof rice, or a Japanese teishoku set meal no longer confuses the system the way it would have two years ago.3 The remaining accuracy gap is in the last mile. Micronutrient estimation from a photo is still unreliable because the difference between a dish cooked in olive oil versus butter, or seasoned with a tablespoon of fish sauce versus soy sauce, is invisible to a camera. Portion estimation without any size or weight reference remains the hardest unsolved problem in visual food logging. A photo of a bowl of rice could be 150 grams or 350 grams and the model has no way to know without a reference object or user confirmation. Depth-sensing hardware in future mobile devices and integration with smart kitchen scales will close this gap, but for now the correction workflow remains essential. Voice-first logging will continue to improve as speech models become more contextually aware and capable of handling multi-item descriptions in a single pass.
Memory and longitudinal personalization will improve. The trajectory toward genuinely personalized nutrition is clear, even if the timeline is measured in years. The combination of vector database architectures and long-context language models will make it feasible for a platform to maintain a meaningful behavioral and nutritional history across months or years. "Based on your patterns over the past six months, you tend to undereat protein by about 25 percent in the two days after your long runs, which coincides with your reported fatigue peaks." That kind of insight requires genuine memory, and current consumer platforms do not deliver it reliably.
The convergence of nutrition, training, recovery, and sleep intelligence into a single integrated system will deepen. The biological connections between these domains are real, and the best decision-support systems will ultimately treat them as an integrated loop rather than separate modules.
What Stays Hard
The majority of people will fail. That is the blunt reality of every fitness and nutrition product ever built. Across books, gyms, online courses, and fitness apps, completion rates cluster around 10 percent. From my time leading product at Freeletics, I saw firsthand that of every 1,000 people who signed up for the app, only 15 would finish a 12-week training plan. The nutrition category is no different. The people reading this article are self-selected for motivation and interest, and even among this group, most will not sustain a behavior change longer than three months. No amount of intelligent software changes the fact that changing how you eat is one of the hardest things a person can do. Software can reduce friction, surface insights, and close feedback loops. It cannot make you care on the Wednesday night when you are exhausted and the easier choice is to skip logging and order takeout.15 You have to find that motivation in yourself.
True metabolic individualization remains the category's most tantalizing unsolved problem. We can sequence your genome for under $200. A CGM sensor can stream your glucose response to every meal in real time. Gut microbiome panels can characterize your digestive ecosystem in detail that would have been science fiction a decade ago. The data exists. What does not exist is the consumer software that reliably translates those signals into daily nutrition targets that produce measurably better outcomes than evidence-based population recommendations for healthy individuals. The gap between "we can measure this about you" and "we can act on it in your daily meal plan" is where the most important research in the category is happening right now. Closing that gap is a decade-scale problem that depends on clinical validation, not just engineering.13 Even the leading consumer CGM apps have no pattern intelligence surfacing insights between food and glucose response, putting the burden on the user.
Causality will remain the hardest claim to make honestly. People want the system to tell them that this food caused their poor sleep or that this macro split caused their plateau. The reality is that the measurement error in both food intake and wearable health data, combined with the uncontrolled variables of real life, makes confident causal statements irresponsible. The more honest and more useful approach is to treat observations as hypotheses and give users the tools to test them. You slept poorly three times this month after eating more than 100g of carbohydrates within two hours of bed. That is a pattern worth investigating, and the system can help you run a controlled experiment over the next two weeks by flagging those nights and tracking whether the pattern holds. That is not causation. It is structured curiosity, and it is more valuable than a confident story that might be wrong.
10Conclusion
The gap between what nutrition software has been and what it can become is large enough to matter for your health. For twenty years, the best available tools recorded what you ate and left you alone with the numbers. The category we are building does something fundamentally different. It watches what you do, learns how your body responds, tells you what to change and why, and gets better at all of those things the longer you use it.
We are early. Fuel runs Bayesian scoring models that learn your meal timing patterns from five days of data and improve their confidence over 28-day windows. Our next-meal recommendation engine scores candidates across eight factors including macronutrient fit, micronutrient gaps, dietary preferences, and rotation decay so you do not eat the same thing three days in a row. We track 30+ micronutrients with targets that adjust by age and sex, down to the shift in magnesium requirements when a male user crosses 31. Our adaptive TDEE uses 14-day recency-weighted trend data with a 300-calorie daily cap on adjustments to prevent overcorrection. We run a 177,000-food database locally on your device so logging works without a network connection. We ship in 11 languages. None of this is enough.
Our personalization is behavior-responsive, not yet biologically informed. We cannot integrate your bloodwork or your CGM data into your targets today. Our meal schedule estimator needs five days of data before it produces anything useful, and a new user on day two gets generic timing. Our re-engagement when someone goes silent for two weeks is a notification, not a conversation. We know exactly where the gaps are, and closing them is what we are building toward every day.
But the version that exists today already answers questions that no nutrition app in history could answer. Whether your weekly execution matched your intent. Whether your training-day fueling is setting you up to perform or to suffer. Whether the plateau you hit is real or noise. Whether the single change that would move you forward is more protein at breakfast or fewer calories on Saturday. Those answers used to require a dedicated coach who knew your data intimately. Now they require software that was built to care about the same things a great coach cares about.
The question is not whether performance nutrition intelligence will reshape how people eat and train. It is whether you will be one of the 15 out of 1,000 who stays long enough to find out what it can do.
For the science behind AI-powered nutrition recommendations, see The Science Behind AI-Powered Nutrition. For a product-level view of personalization, see The Role of AI in Personalized Nutrition. For day-to-day logging workflows, see Easy Ways to Log Food and Track Macros with AI.
11References
Footnotes
Fakih El Khoury C, et al. The Effects of Dietary Mobile Apps on Nutritional Outcomes in Adults with Chronic Diseases: A Systematic Review and Meta-Analysis. Journal of the Academy of Nutrition and Dietetics. 2019;119(4):626-651. https://pubmed.ncbi.nlm.nih.gov/30686742/ Turner-McGrievy GM, et al. Defining Adherence to Mobile Dietary Self-Monitoring and Assessing Tracking Over Time. Journal of the Academy of Nutrition and Dietetics. 2019;119(9):1516-1524. https://pubmed.ncbi.nlm.nih.gov/31155473/
↩Ordovas JM, et al. Precision nutrition: Maintaining scientific integrity while realizing market potential. Precision Nutrition report and review on the need for strong methods, validated inputs, and careful interpretation of complex data streams in performance nutrition systems. https://pmc.ncbi.nlm.nih.gov/articles/PMC9481417/
↩JMIR Scoping Review. AI-Based Dietary Assessment: Accuracy and Limitations. November 2024. AI photo logging systems in controlled settings achieve nutrient estimation errors of 10-15%, with food detection accuracy ranging from 74% to near-perfect for single common foods under good lighting. https://pmc.ncbi.nlm.nih.gov/articles/PMC11638690/
↩Li X, et al. Evaluating the Quality and Comparative Validity of Manual Food Logging and Artificial Intelligence-Enabled Food Image Recognition in Apps for Nutrition Care. Nutrients. 2024;16(15):2573. Beef pho overestimated by 49%, bubble tea underestimated by 76%. Manual apps overestimated Western diet energy by 1040 kJ and underestimated Asian diet energy by -1520 kJ. https://pubmed.ncbi.nlm.nih.gov/39125452/
↩Patel ML, Wakayama LN, Bennett GG. Self-Monitoring via Digital Health in Weight Loss Interventions: A Systematic Review Among Adults with Overweight or Obesity. Obesity. 2021;29(3):478-499. https://pubmed.ncbi.nlm.nih.gov/33624440/ Also: Burke LE, et al. A systematic review of the use of dietary self-monitoring in behavioural weight loss interventions: delivery, intensity and effectiveness. Public Health Nutrition. 2011;14(4):659-669. https://www.cambridge.org/core/journals/public-health-nutrition/article/systematic-review-of-the-use-of-dietary-selfmonitoring-in-behavioral-weightloss-interventions-delivery-intensity-and-effectiveness/476B83589088637C6740BA801B92185D
↩Hall KD, et al. Energy balance and its components: implications for body weight regulation. American Journal of Clinical Nutrition. 2012;95(4):989-994. https://pubmed.ncbi.nlm.nih.gov/22434603/ Levine JA, Eberhardt NL, Jensen MD. Role of nonexercise activity thermogenesis in resistance to fat gain in humans. Science. 1999;283(5399):212-214. https://pubmed.ncbi.nlm.nih.gov/9880251/
↩Hall KD, Chow CC. Estimating changes in free-living energy intake and its confidence interval. American Journal of Clinical Nutrition. 2011;94(1):66-74. https://pubmed.ncbi.nlm.nih.gov/21562087/ MacroFactor's public product documentation describes a similar trend-weight and logged-intake approach to estimating expenditure. https://macrofactor.com/expenditure-v3/
↩Bangsbo J, Hostrup M, Hellsten Y, et al. Consensus Statements: Optimizing Performance of the Elite Athlete. Scand J Med Sci Sports. 2025;35(8):e70112. https://doi.org/10.1111/sms.70112/
↩Morton RW, Murphy KT, McKellar SR, et al. A systematic review, meta-analysis and meta-regression of the effect of protein supplementation on resistance training-induced gains in muscle mass and strength in healthy adults. Br J Sports Med. 2018;52(6):376-384. https://pubmed.ncbi.nlm.nih.gov/28698222/ Mamerow MM, Mettler JA, English KL, et al. Dietary protein distribution positively influences 24-h muscle protein synthesis in healthy adults. J Nutr. 2014;144(6):876-880. https://pubmed.ncbi.nlm.nih.gov/24477298/
↩Gejl KD, Nybo L. Performance effects of periodized carbohydrate restriction in endurance trained athletes: a systematic review and meta-analysis. Journal of the International Society of Sports Nutrition. 2021;18:37. https://pubmed.ncbi.nlm.nih.gov/34001184/
↩2025 SMARTER mHealth trial published in Obesity. Confirmed significant positive association between dietary self-monitoring adherence and weight management outcomes in a 12-month digital health context. https://pmc.ncbi.nlm.nih.gov/articles/PMC11897847/
↩Lichtman SW, et al. Discrepancy between Self-Reported and Actual Caloric Intake and Exercise in Obese Subjects. New England Journal of Medicine. 1992;327(27):1893-1898. Obese subjects underreported intake by an average of 47% compared to doubly labeled water measurements. Food labels carry a plus-or-minus 20% legal tolerance in many jurisdictions. https://pubmed.ncbi.nlm.nih.gov/1454084/
↩Zeevi D, et al. Personalized Nutrition by Prediction of Glycemic Responses. Cell. 2015;163(5):1079-1094. Showed wide person-to-person variability in glycemic response to identical foods across 800 participants and 46,898 meals. CGM-guided personalization in healthy non-diabetic individuals remains emerging rather than established for consumer-grade autonomous recommendation. https://www.weizmann.ac.il/immunology/elinav/sites/immunology.elinav/files/2022-06/Personalized%20Nutrition%20by%20Prediction%20of%20Glycemic%20Responses.pdf
↩Alowais SA, Alghamdi SS, Alsuhebany N, et al. Revolutionizing healthcare: the role of artificial intelligence in clinical practice. BMC Medical Education. 2023;23:689. https://pmc.ncbi.nlm.nih.gov/articles/PMC10517477/ Liu J, Wang C, Liu S. Utility of ChatGPT in Clinical Practice. Journal of Medical Internet Research. 2023;25:e48568. https://www.jmir.org/2023/1/e48568/
↩
